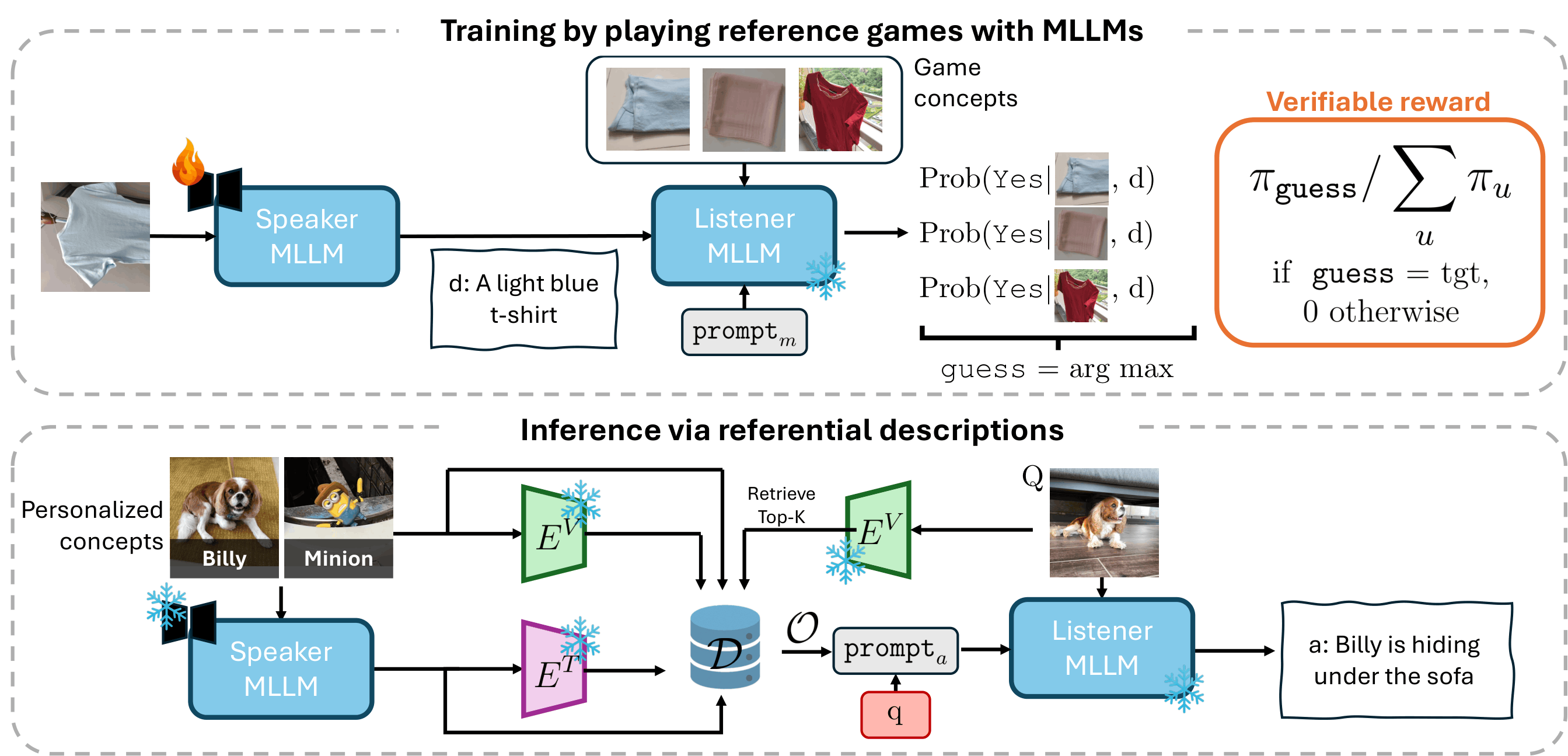
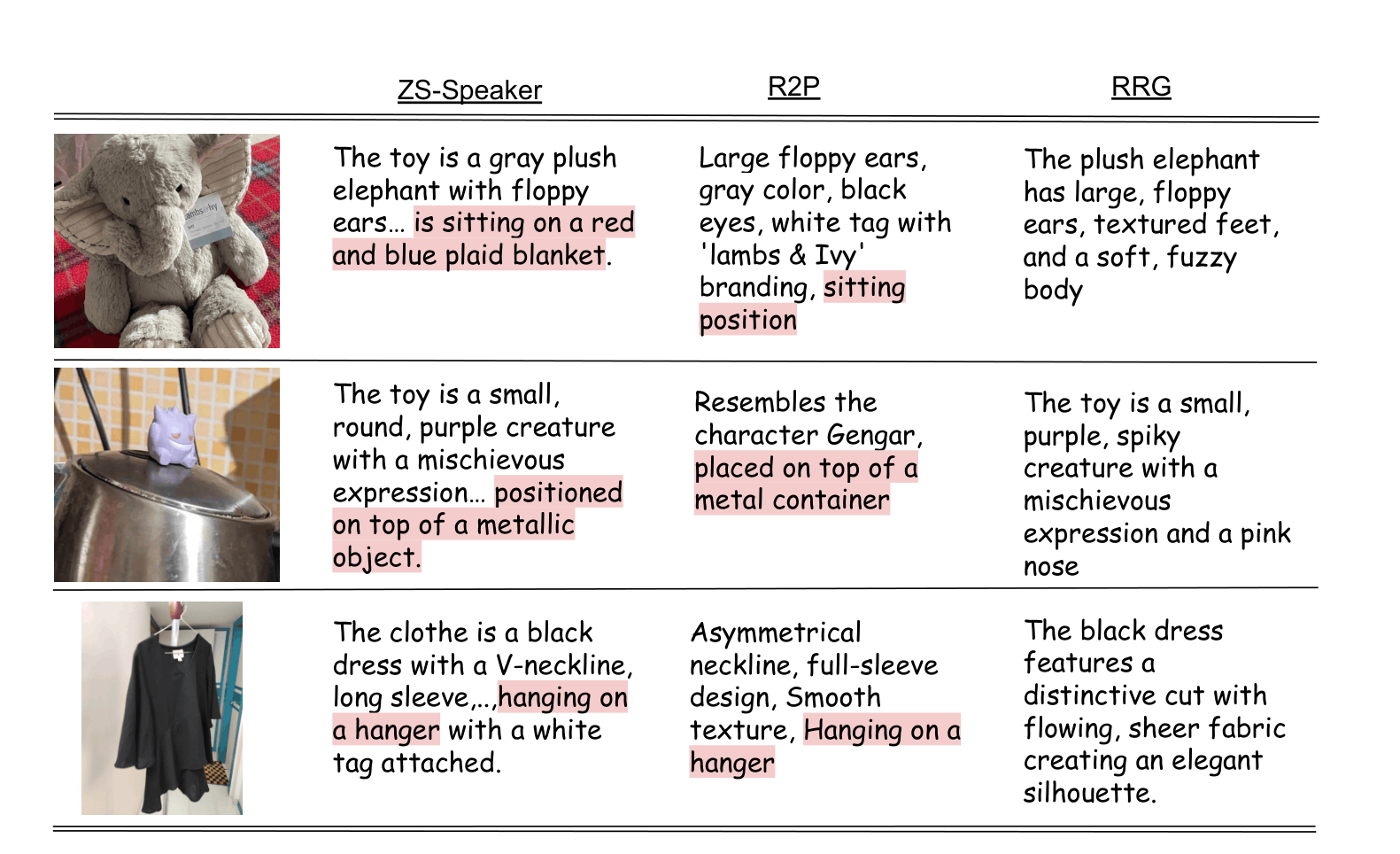
Personalizing Multimodal Large Language Models (MLLMs) aims to recognize users' unique concepts from visual data and provide personalized responses. Although prior work has shown the benefit of concept descriptions and reasoning for this task, MLLM descriptions often include information, such as state and context, that does not help and may in fact hinder the unique identification of the target concept among other visually similar items.
Effective descriptions of personal concepts should instead be accurate, discriminative, and free of distracting details. To achieve such descriptions, we introduce Reinforced Reference Game (RRG), a learning framework that promotes discriminative descriptions through a novel reinforced multimodal reference game.
The MLLM plays both the roles of speaker and listener in a contrastive game setting, whose goal is to effectively communicate discriminative information about a target concept. Our approach formulates a verifiable contrastive reward over hard positives (dissimilar views of the same concept) and hard negatives (visually similar but different concepts).
Empirically, RRG achieves state-of-the-art across multiple tasks on three personalization benchmarks. RRG generalizes to unseen domains and outperforms existing methods based on concept descriptions and personalization-specific RL frameworks.